-
1 genome instability
Англо-русский словарь по биотехнологиям > genome instability
-
2 region
1) область, район, зона2) анат. полостьbreakpoint cluster region — область локализации сайта инициации реаранжировки ( иммуноглобулиновых генов)
budding region — «бадинг»-район (участок тела у беспозвоночных, не отторгающий пересаженный аллогенный лоскут)
С region — константная область, С-область, С-домен, С-сегмент ( иммуноглобулина)
choleragenoid region — область связывания в холерном энтеротоксине, B-субъединица, холерагеноид
complementarity-determining region — гипервариабельный участок, hv-участок ( в молекуле антитела)
constant region — константная область, С-область, С-домен, С-сегмент ( иммуноглобулина)
cortico-medullary region — кортикомедуллярная область, кортикомедуллярная зона (напр. тимуса)
DH-encoded region — DH-область гена, DH-сегмент гена (область генома, кодирующая D-фрагмент тяжёлой цепи иммуноглобулина)
exchanged region — рекомбинировавший участок, рекомбинировавший сегмент
Fd region — Fd-фрагмент, Fd-область ( участок H-цепи Fab-фрагмента иммуноглобулиновой молекулы)
flanking region — ограничивающая [фланкирующая] область
framework region — остовная [каркасная, скелетная] область ( иммуноглобулина)
hinged region — шарнирная область, область «талии» ( в молекуле иммуноглобулина)
hypervariable region — гипервариабельный участок, hv-участок ( в молекуле антитела)
immune response region — область генов иммунного ответа, область Ir-генов, Ir-область
invariable region — константная область, C-область, C-домен, C-сегмент ( иммуноглобулина)
Ir region — область генов иммунного ответа, область Ir-генов, Ir-область
JH-encoded region — JH-область гена, JH-сегмент гена (область генома, кодирующая J-фрагмент тяжёлой цепи иммуноглобулина)
link region — шарнирная область, область «талии» ( в молекуле иммуноглобулина)
moderately variable region — последовательность со средней частотой изменчивости, средневариабельная последовательность (в составе вариабельной области иммуноглобулина или соответствующего сегмента гена)
octamer region — октамерная область (участок гена длиной 8 нуклеотидных пар, обладающий регуляторной функцией)
switch region — 1) сайт [область] переключения, свич-сайт ( в составе последовательности иммуноглобулиновых генов) 2) S-область (последовательность аминокислот в месте сочленения вариабельных и константных областей цепей иммуноглобулинов)
V region — вариабельная область, V-область, V-домен, V-сегмент ( иммуноглобулина)
variable region — вариабельная область, V-область, V-домен, V-сегмент ( иммуноглобулина)
VH-encoded region — VH-область гена, VH-сегмент гена (область генома, кодирующая вариабельный фрагмент тяжёлой цепи иммуноглобулина)
-
3 repetition frequency
Число копий данной повторяющейся последовательности ДНК в расчете на 1 геном; формально (обозначается f) равна отношению химической chemical complexity и кинетической kinetic complexity сложности генома; Ч.п. и сложность генома являются основными числовыми характеристиками данного фрагмента генома.* * *Повторений частота — число копий (f) определенной последовательности ДНК, присутствующей в гаплоидном наборе (в расчете на 1 геном). Формально f равно отношению химической и кинетической сложности генома, т. обр., П. ч. и сложность генома — основные числовые характеристики каждого фрагмента генома.Англо-русский толковый словарь генетических терминов > repetition frequency
-
4 DH-encoded region
1) Биология: DH-область гена (область генома, кодирующая D-фрагмент тяжёлой цепи иммуноглобулина), DH-сегмент гена (область генома, кодирующая D-фрагмент тяжёлой цепи иммуноглобулина)2) Макаров: DH-область гена (область генома, кодирующая D-фрагмент тяжелой цепи иммуноглобулина), DH-сегмент гена (область генома, кодирующая D-фрагмент тяжелой цепи иммуноглобулина) -
5 genome size
Количество пар оснований ДНК в расчете на гаплоидный геном; иногда (что неверно) понятие «В.г.» используется для обозначения весового содержания ДНК (в пикограммах на клетку) либо общей длины составляющих геном или кариотип хромосом (в этом случае правильнее - общая длина генома, total genome length).см. рис.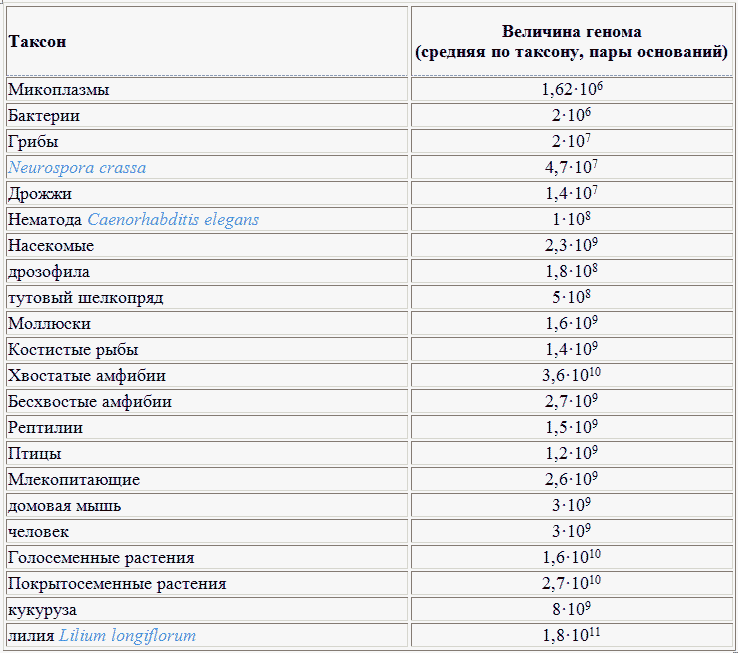 * * *Генома величина — количество пар оснований (п. о.) в расчете на гаплоидный геном (см. Гаплоидный набор). Г. в. основных таксонов представлены в таблице (по Арефьеву, Лисовенко, 1995).
* * *Генома величина — количество пар оснований (п. о.) в расчете на гаплоидный геном (см. Гаплоидный набор). Г. в. основных таксонов представлены в таблице (по Арефьеву, Лисовенко, 1995).
Англо-русский толковый словарь генетических терминов > genome size
-
6 genomic formula
Краткая математическая запись числа и состава хромосомных наборов индивидуального генома: n( гаплоидный), 2n( диплоидный), AABB (тетраплоидный набор, состоящий из двух диплоидных геномов), 2n-1 (моносомический) и т.д.* * *Геномная формула, ф. генома — математическое представление (краткая математическая запись) геномов отдельных особей, отражающее их генетические характеристики: число и состав наборов хромосом. Напр., N или n — гаплоидная гамета или моноплоидная соматическая клетка, 2N (2n) — диплоид, 3N (3n) — триплоид, 4N (4n) — тетраплоид, 2N–1 (2n–1) — моносомик, 2N +1 (2n+1) — трисомик, 2N–2 (2n–2) — нуллисомик и т.д.Англо-русский толковый словарь генетических терминов > genomic formula
-
7 hybridogenesis
Способ существования особей (популяций), при котором постоянно сохраняется гибридный состав их генома (без объединения родительских геномов), классический пример Г. - прудовая лягушка "Rana esculenta", являющаяся постоянно воспроизводящимся гибридом лягушек R.ridibunda и R.lessonae, у прудовой лягушки в соматических клетках имеются оба родительских гаплоидных генома, а в гаметах - только геном R.lessonae; также в симпатрических популяциях происходит постоянная гибридизация собственно R.ridibunda и R.lessonae.* * *Гибридогенез — способ существования некоторых популяций, в которых особи являются межвидовыми гибридами и гибридный состав их генома постоянно поддерживается, но без объединения родительских геномов — гаметы у этих особей несут ядерный геном только одного из родительских видов. Примером Г. являются прудовые лягушки Rana esculenta, являющиеся постоянно воспроизводящимися гибридами от скрещивания особей видов R. lessonae и R. ridibunda, но в гаметах R. esculenta обнаруживается геном только R. lessonae. В симпатрических популяциях (см. Симпатрия) происходит постоянная гибридизация собственно R. ridibunda и R. lessonae.Англо-русский толковый словарь генетических терминов > hybridogenesis
-
8 subgenomic transcript
«Усечённый» транскрипт ретровирусной ДНК (после обратной транскрипции с РНК-генома ретровируса), содержащий только последовательность нуклеотидов гена env, кодирующего белок оболочки; в состав полноразмерного транскрипта генома ретровируса входят гены env, pol (кодирует обратную транскриптазу reverse transcriptase) и gag (кодирует белок кора вирусной частицы); С.г. сохраняет регуляторные сегменты вирусного генома и поэтому используется в генной инженерии, например, при конструировании сплайсинг-вектора splicing-vector.Англо-русский толковый словарь генетических терминов > subgenomic transcript
-
9 restriction analysis
1) Биология: (enzyme digest) рестрикционное картирование (генома), (enzyme digest) рестрикционный анализ (генома), рестрикционный анализ2) Макаров: рестрикционное картирование (генома) -
10 transposon
[træn'spəʊzɒn]1) Биология: длинный "прыгающий" ген (переносчик генетической информации), транспозон (участок генома с непостоянной локализацией)2) Техника: транспозон (мигрирующий генетический элемент)3) Макаров: Тп-элемент (участок генома с непостоянной локализацией), перемещающийся элемент (участок генома с непостоянной локализацией) -
11 Bioinformatics
Биоинформатика — новое направление исследований, использующее математические и алгоритмические методы для решения молекулярно-биологических задач. В отечественной генетике зарождение этого направления тесно связано со становлением и развитием Института цитологии и генетики СО АН СССР в Новосибирском Академгородке. Первая международная конференция по Б. регуляции и структуры генома в странах СНГ была организована и проведена в этом институте (24–31 августа 1998 г.). Совершенствование экспериментальных методов приводит к экспоненциальному росту молекулярно-биологических данных и возникновению абсолютно новой для биологии междисциплинарной задачи анализа и хранения информации из лабораторий, рассеянных по всему миру. Задачи Б. можно определить как развитие и использование математических и компьютерных методов для решения проблем молекулярной биологии. Выделяют: (1) Задачу поддержания и обновления баз данных. Современная эра в молекулярной биологии началась с момента открытия двойной спирали Уотсоном и Криком в 1953 г. Эта революция породила большой объем данных полученных прямым чтением ДНК из разных участков геномов. Быстрое секвенирование стало возможно 10 лет назад, первый полностью секвенированный геном — геном бактерии Haemophilus influenzae, 1800 т.п.н. В 1996 г. закончено секвенирование первого генома эукариот, генома дрожжей (10 млн п.н.) и секвенирование продолжается со скоростью более 7 миллионов нуклеотидов в год. Знание геномной ДНК в значительной мере сделало возможным ряд фундаментальных биологических открытий, таких как интроны, самосплайсирующиеся РНК (см. РНК-процессинг), обратная транскрипция и псевдогены. Однако существующие базы данных не вполне адекватны требованиям молекулярных биологов: одной из нерешенных проблем является создание программного обеспечения для простого и гибкого доступа к данным. (2) Другой класс задач в большей степени ориентирован на поиск оптимальных алгоритмов для анализа последовательностей. Типичным примером такой задачи является задача выравнивания: как выявить сходство между двумя последовательностями, зная их нуклеотидный состав? Задача решается множество раз в день, поэтому нужен оптимальный алгоритм с минимальным временем выравнивания. (3) Можно также выделить ряд направлений современной Б.: создание и поддержка баз данных (БД) регуляторных последовательностей и белков; БД по регуляции генной экспрессии; БД по генным сетям; компьютерный анализ и моделирование метаболических путей; компьютерные методы анализа и распознавания в геноме регуляторных последовательностей; методы анализа и предсказания активности функциональных сайтов в нуклеотидных последовательностях геномов; компьютерные технологии для изучения генной регуляции; предсказания структуры генов; моделирование транскрипционного и трансляционного контроля генной экспрессии; широкомасштабный геномный анализ и функциональное аннотирование нуклеотидных последовательностей; поиск объективных методов аннотирования и выявления различных сигналов в нуклеотидных последовательностях; эволюция регуляторных последовательностей в геномах; характеристики белковой структуры, связанные с регуляцией; экспериментальные исследования механизмов генной экспрессии и развитие интерфейса, связывающего экспериментальные данные с компьютерным анализом геномов. Первые работы по компьютерному анализу последовательностей биополимеров появились еще в 1960-1970-х годах, однако формирование вычислительной биологии как самостоятельной области началось в 1980-х годах после развития методов массового секвенирования ДНК. С точки зрения биолога-экспериментатора, можно выделить пять направлений вычислительной биологии: непосредственная поддержка эксперимента (физическое картирование (см. Физическая карта), создание контиг (см.) и т.п.), организация и поддержание банков данных, анализ структуры и функции ДНК и белков, эволюционные и филогенетические исследования, а также собственно статистический анализ нуклеотидных последовательностей. Разумеется, границы между этими направлениями в значительной мере условны: результаты распознавания белок-кодирующих областей используются в экспериментах по идентификации генов, одним из основных методов предсказания функции белков является поиск сходных белков в базах данных, а для осуществления детального предсказания клеточной роли белка необходимо привлекать филогенетические соображения. В 1982 г. возникли GenBank и EMBL — основные банки нуклеотидных последовательностей. Вскоре после этого были созданы программы быстрого поиска по банку — FASTA и затем BLAST. Позднее были разработаны методы анализа далеких сходств и выделения функциональных паттернов в белках. Оказалось, что даже при отсутствии близких гомологов, можно достаточно уверенно предсказывать функции белков. Эти методы с успехом применялись при анализе вирусных геномов, а затем и позиционно клонированных генов человека. Алгоритмы анализа функциональных сигналов в ДНК ( промоторов, операторов, сайтов связывания рибосом) менее надежны, однако и они в ряде случаев были успешно применены, напр., при анализе пуринового регулона Escherichia coli. Идет активная работа над созданием алгоритмов предсказания вторичной структуры РНК. Алгоритмические аспекты этой проблемы были разрешены достаточно быстро, однако оказалось, что точность экспериментально определенных физических параметров не позволяет осуществлять надежные предсказания. В то же время, сравнительный подход, позволяющий построить общую структуру для группы родственных или выполняющих одну и ту же функцию РНК, дает существенно более точные результаты. Другим важным достижением, связанным с рибосомальными РНК, стало построение эволюционного древа прокариот и вытекающей из него естественной классификации бактерий, используемой в банках нуклеотидных последовательностей, в частности GenBank. Статистическая информация (в виде предсказания GenScan), последовательности гомологичных белков и последовательности EST являются исходным материалом для предсказания генов в последовательностях ДНК человека программой ААТ. Алгоритмы, объединяющие анализ функциональных сигналов в нуклеотидных последовательностях и предсказание вторичной структуры РНК, используются для поиска генов тРНК и самосплайсирующихся интронов. Одновременный анализ белковых гомологий и функциональных сигналов позволил получить интересные результаты при эволюцию системы репликации по механизму катящегося кольца. Опыт показывает, что надежное предсказание функции белка по аминокислотной последовательности возможно лишь при одновременном применении разнонаправленных программ структурного и функционального анализа. Основное — это приближение теоретических методов к биологической практике. Во-первых, вновь создаваемые алгоритмы все ближе имитируют работу биолога. В частности, был формализован итеративный подход к поиску родственных белков в банках данных, позволяющий работать со слабыми гомологиями и искать отдаленные члены белковых семейств. При этом все члены семейства, идентифицированные на очередном шаге, используются для создания очередного образа семейства, являющегося основой для следующего запроса к базе данных. Другим примером являются алгоритмы, формализующие сравнительный подход к предсказанию вторичной структуры регуляторных РНК. Во-вторых, создаваемые алгоритмы непосредственно приближаются к экспериментальной практике. Так, повышение избирательности методов распознавания белок-кодирующих областей (возможно, за счет уменьшения чувствительности) позволяет осуществлять предсказание специфичных гибридизационных зондов и затравок ПЦР. Наконец, развитие Интернета — электронной почты и затем WWW — сняло зависимость от модели компьютера и операционной системы и сделало программы универсальным рабочим инструментом.Англо-русский толковый словарь генетических терминов > Bioinformatics
-
12 genome size
величина генома
Количество пар оснований ДНК в расчете на гаплоидный геном; иногда (что неверно) понятие «В.г.» используется для обозначения весового содержания ДНК (в пикограммах на клетку) либо общей длины составляющих геном или кариотип хромосом (в этом случае правильнее - общая длина генома).
[Арефьев В.А., Лисовенко Л.А. Англо-русский толковый словарь генетических терминов 1995 407с.]Тематики
EN
Англо-русский словарь нормативно-технической терминологии > genome size
-
13 kinetic complexity
- кинетическая сложность [генома]
кинетическая сложность [генома]
Сложность генома, определяемая параметрами кинетики реассоциации ДНК, указывающими на вхождение в нее последовательностей различного типа - уникальных, умеренно повторяющихся и высокоповторяющихся, в случае уникальных последовательностей имеет место совпадение значений К.с. и химической сложности.
[Арефьев В.А., Лисовенко Л.А. Англо-русский толковый словарь генетических терминов 1995 407с.]Тематики
EN
Англо-русский словарь нормативно-технической терминологии > kinetic complexity
-
14 genomic sequencing
определение (расшифровка) нуклеотидной последовательности генома
Расшифровка структуры генома путем выявления точной последовательности нуклеотидов
[Англо-русский глоссарий основных терминов по вакцинологии и иммунизации. Всемирная организация здравоохранения, 2009 г.]Тематики
- вакцинология, иммунизация
EN
Англо-русский словарь нормативно-технической терминологии > genomic sequencing
-
15 genomic formula
формула генома
Краткая математическая запись числа и состава хромосомных наборов индивидуального генома: n (гаплоидный), 2n (диплоидный), AABB (тетраплоидный набор, состоящий из двух диплоидных геномов), 2n-1 (моносомический) и т.д.
[Арефьев В.А., Лисовенко Л.А. Англо-русский толковый словарь генетических терминов 1995 407с.]Тематики
EN
Англо-русский словарь нормативно-технической терминологии > genomic formula
-
16 chemical complexity
- химическая сложность [генома]
химическая сложность [генома]
Сложность генома, определяемая порядком расположения пар нуклеотидов в ДНК; совпадение значений Х.с. и кинетической сложности свидетельствует о том, что данный фрагмент ДНК представлен уникальной (неповторяющейся) последовательностью.
[Арефьев В.А., Лисовенко Л.А. Англо-русский толковый словарь генетических терминов 1995 407с.]Тематики
EN
Англо-русский словарь нормативно-технической терминологии > chemical complexity
-
17 repetition frequency
частота повторяемости
Число копий данной повторяющейся последовательности ДНК в расчете на 1 геном; формально (обозначается f) равна отношению химической и кинетической сложности генома; Ч.п. и сложность генома являются основными числовыми характеристиками данного фрагмента генома.
[Арефьев В.А., Лисовенко Л.А. Англо-русский толковый словарь генетических терминов 1995 407с.]Тематики
EN
Англо-русский словарь нормативно-технической терминологии > repetition frequency
-
18 merogenote
Большой англо-русский и русско-английский словарь > merogenote
-
19 merogenote
-
20 мерогенота
(гибридный геном, состоящий из генома реципиента и части генома донора) merogenote
См. также в других словарях:
C-парадокс (избыточность генома) — С парадокс отсутствие корреляции между физическими размерами генома и сложностью организмов. Количество ДНК в гаплоидном геноме обозначают латинским символом С, где «С» означает «константный» (англ. constant) или «характерный» (англ.… … Википедия
Расшифровка генома неандертальца — Институт эволюционной антропологии имени Макса Планка, Лейпциг В июле 2006 года Институт эволюционной антропологии имени Макса Планка в Г … Википедия
Упаковка генома — * упакоўка генома * genome packing внедрение вирусного генома в пустую полость вириона. Механизм упаковки генома объясняет гипотеза прокапсида … Генетика. Энциклопедический словарь
ПРОЕКТ ГЕНОМА ЧЕЛОВЕКА — ПРОЕКТ ГЕНОМА ЧЕЛОВЕКА, международная научная программа, начатая в 1988 г., цель которой составление карты человеческого ГЕНОМА путем анализа 100 000 или более составляющих его ГЕНОВ, установления их расположения в пределах человеческих хромосом … Научно-технический энциклопедический словарь
Нестабильность генома — радиационно индуцированная (РИНСГ) возникновение de novo множественных генетических нарушений неклонального характера у 10 30 % потомков облучённых клеток, выживших после облучения. Радиационно индуцированная нестабильность генома пepeдaётcя … Википедия
Мобильные элементы генома — последовательности ДНК, способные перемещаться внутри генома живых организмов. Существует несколько классов мобильных элементов генома, отличающихся по строению и способу перемещения: Инсерционные элементы, например, IS1603 Транспозоны, например … Википедия
Упаковка генома — внедрение вирусного генома в пустую полость вириона. Механизм упаковки генома объясняет гипотеза прокапсида (см.). (Источник: «Словарь терминов микробиологии») … Словарь микробиологии
величина генома — genome size величина генома. Количество пар оснований ДНК в расчете на гаплоидный геном; иногда (что неверно) понятие “В.г.” используется для обозначения весового содержания ДНК (в пикограммах на клетку) либо общей длины составляющих геном или… … Молекулярная биология и генетика. Толковый словарь.
Сборка генома — Перекрывающиеся фрагменты образуют контиги, контиги с промежутками известной длины образуют скаффолды. Сборка генома процесс объединения большого количества коротких фрагментов ДНК (ридов) в одну или несколько длинных последовательностей… … Википедия
Кинетическая сложность генома — * кінетычная складанасць генома * kinetic genome complexity сложность генома, определяемая параметрами кинетики реассоциации ДНК, которые указывают на вхождение в нее уникальных, умеренно и высокоповторяющихся последовательностей. В случае… … Генетика. Энциклопедический словарь
Метод случайного разрезания генома рестриктазами — * метад выпадковага разразання генома рэстрыктазамі * shortgun experiment клонирование генома в виде случайно образованных фрагментов … Генетика. Энциклопедический словарь