-
1 bounded
1) граничить
2) ограниченный
3) ограниченно
4) разграниченный
5) связанный ∙ absolutely bounded form ≈ абсолютно ограниченная форма absolutely bounded function ≈ ограниченная по абсолютной величине функция absolutely bounded matrix ≈ абсолютно ограниченная матрица algebra of bounded representation type ≈ алгебра с ограниченными степенями представлений algebra of linearly bounded degree ≈ алгебра линейно ограниченной степени almost bounded function ≈ функция, ограниченная почти всюду bounded above function ≈ ограниченная сверху функция bounded above operator ≈ ограниченый сверху оператор bounded above subset ≈ ограниченное сверху подмножество bounded below function ≈ ограниченная снизу функция bounded below operator ≈ ограниченный снизу оператор bounded below subset ≈ ограниченное снизу подмножество bounded closed interval ≈ ограниченный замкнутый интервал bounded distance decoding ≈ декодирование с ограниченным расстоянием bounded from one side ≈ полуограниченный bounded open interval ≈ ограниченный открытый интервал bounded partial quotient ≈ ограниченное неполное частное bounded pure subgroup ≈ ограниченная сервантная подгруппа bounded random variable ≈ ограниченная случайная величина bounded universal hypothesis ≈ ограниченная универсальная гипотеза bounded variable technique ≈ метод ограниченной переменной collectively bounded set ≈ ограниченное в совокупности множество completely bounded set ≈ вполне ограниченное множество completely bounded space ≈ вполне органическое пространство completely bounded statistic ≈ вполне ограниченная статистика derivative of bounded variation ≈ производная с ограниченной вариацией doubly bounded quantifier ≈ ограниченный с двух сторон квантор essentially bounded function ≈ существенно ограниченная функция essentially bounded random variable ≈ существенно ограниченная случайная величина essentially bounded sequence ≈ существенно ограниченная последовательность explicitly bounded function ≈ явно ограниченная функция finitely bounded germ ≈ конечно ограниченный росток function of bounded characteristic ≈ функция с ограниченной характеристикой function of bounded type ≈ функция ограниченного вида function of bounded variation ≈ функция с ограниченным изменением linearly bounded automaton ≈ линейно ориентированный автомат linearly bounded set ≈ линейно ограниченное множество locally bounded curvature ≈ локально ограниченная кривизна locally bounded density ≈ локально ограниченная плотность locally bounded function ≈ локально ограниченная функция locally bounded game ≈ локально ограниченная игра locally bounded space ≈ локально ограниченное пространство metrically bounded functional ≈ метрически ограниченный функционал metrically bounded set ≈ метрически ограниченное множество nontangentially bounded function ≈ нетангенциально ограниченная функция nontangentially bounded integral ≈ некасательно ограниченный интеграл order bounded functional ≈ ограниченный по упорядоченности функционал pointwise bounded function ≈ точечно ограниченная функция polynomially bounded function ≈ полиномиально ограниченная функция process with bounded aftereffect ≈ процесс с ограниченным последействием progressively bounded graph ≈ прогрессивно ограниченный граф recursively bounded quantifier ≈ рекурсивно ограниченный квантор regressively bounded graph ≈ регрессивно ограниченный граф relatively bounded form ≈ относительно ограниченная форма sequentially bounded net ≈ последовательно ограниченная сеть simply bounded subset ≈ поточечно ограниченное подмножество smoothly bounded region ≈ гладко ограниченная область stochastically bounded sequence ≈ стохастически ограниченная последовательность strictly bounded set ≈ строго ограниченное множество strongly bounded set ≈ сильно ограниченное множество strongly bounded space ≈ сильно ограниченное пространство theor of semigroups of linear bounded operators ≈ теория полугрупп линейных ограниченных операторов topology of bounded convergence ≈ топология ограниченной сходимости totally bounded measure ≈ вполне ограниченная мера totally bounded set ≈ вполне ограниченное множество totally bounded space ≈ вполне ограниченное пространство totally bounded subset ≈ вполне ограниченное подмножество totally bounded uniformity ≈ вполне ограниченная равномерность uniformly bounded convergence ≈ равномерно ограниченная сходимость uniformly bounded curvature ≈ равномерно ограниченная кривизна uniformly bounded error ≈ равномерно ограниченная ошибка uniformly bounded family ≈ равномерно ограниченное семейство uniformly bounded function ≈ равномерно ограниченная функция uniformly bounded kernel ≈ равномерно ограниченное ядро uniformly bounded sequence ≈ равномерно ограниченная последовательность uniformly bounded series ≈ равномерно ограниченный ряд uniformly bounded set ≈ равномерно ограниченное множество uniformly bounded variation ≈ равномерно ограниченная вариация weakly bounded set ≈ слабо ограниченное множество weakly bounded subset ≈ слабо ограниченное подмножество - almost bounded - bounded above - bounded acceptor - bounded accuracy - bounded adele - bounded aggregate - bounded approximation - bounded automaton - bounded axonometry - bounded below - bounded characteristic - bounded collection - bounded compactness - bounded completeness - bounded continuum - bounded convergence - bounded curvature - bounded decomposition - bounded deficiency - bounded degree - bounded derivation - bounded derivative - bounded deviation - bounded difference - bounded distribution - bounded domain - bounded duality - bounded extension - bounded field - bounded flow - bounded form - bounded frontier - bounded function - bounded functional - bounded group - bounded homomorphism - bounded index - bounded integral - bounded integrand - bounded intersection - bounded invertibility - bounded kernel - bounded language - bounded lattice - bounded mapping - bounded martingale - bounded matrix - bounded measure - bounded metric - bounded module - bounded monotonicity - bounded morphism - bounded motion - bounded network - bounded norm - bounded operator - bounded order - bounded path - bounded polyhedron - bounded potential - bounded predicate - bounded problem - bounded product - bounded projection - bounded quality - bounded quantification - bounded quantifier - bounded quantity - bounded quotient - bounded region - bounded representation - bounded retract - bounded semigroup - bounded sequence - bounded series - bounded set - bounded solution - bounded space - bounded spectrum - bounded spline - bounded string - bounded subset - bounded subtraction - bounded sum - bounded summand - bounded support - bounded term - bounded topology - bounded transformation - bounded utility - bounded variance - bounded variation - bounded varying - bounded vector - essentially bounded - explicitly bounded - exponentially bounded - power bounded - uniformly bounded - weakly bounded (математика) ограниченный -
2 RDB
- Совет по научным исследованиям и разработкам (США)
- реляционная база данных
- база данных информации маршрутизации
база данных информации маршрутизации
(МСЭ-T G.7715/ МСЭ-Т Y.1706).
[ http://www.iks-media.ru/glossary/index.html?glossid=2400324]Тематики
- электросвязь, основные понятия
EN
реляционная база данных
База данных, реализованная в соответствии с реляционной моделью данных.
[ ГОСТ 20886-85]
реляционная БД
База данных, логически организованная в виде набора отношений ее компонентов.
Характерной особенностью реляционной базы данных является структура, выполненная в виде таблиц. Строки таких таблиц соответствуют записям, столбцы - атрибутам (признакам хранимых данных). Например, таблица, в которой имеются столбцы: фамилия, год рождения, место работы, домашний адрес, телефон, а в строках записываются эти сведения о сотрудниках предприятия. Такие данные являются ядром реляционной базы.
Использование реляционных баз данных позволяет:
собирать и хранить данные в виде таблиц;
обновлять их содержание;
получать разнообразную информацию по атрибутам или записям;
отображать полученные данные в виде диаграмм или таблиц;
выполнять необходимые расчеты по материалам базы.
(Терминологическая база данных по информатике и бизнесу [Электронный ресурс])
[ http://www.morepc.ru/dict/]
Системы управления реляционными базами данных
Процесс отделения программ от структур данных завершили, в конечном итоге, реляционные базы данных (РБД).
В РБД все данные представлены исключительно в формате таблиц, или, по терминологии реляционной алгебры, отношений (relation). Таблица в реляционной алгебре - это неупорядоченное множество записей (строк), состоящих из одинакового набора полей (столбцов). Каждая строка характеризует некий объект, каждый столбец - одну из его характеристик. Совокупность таких связанных таблиц и составляет БД, при этом таблицы полностью равноправны - между ними не существует никакой иерархии. Реляционная модель является простейшей и наиболее привычной формой представления данных.
Можно было бы привести более строгое определение, но это не является пред-метом настоящей статьи. Здесь нам важно отметить следующее. РБД позволили моделям данных отражать взаимосвязи прикладной области, а не методы программного доступа к данным и структурам данных. Это огромный шаг вперед по нескольким причинам:
Отражающие прикладную область знаний модели данных являются интуитивно понятными конечному пользователю.
Реорганизация данных на физическом уровне совершенно не влияет на выпол-нение прикладных программ. Одним из важнейших побочных эффектов данного преимущества является появление клиент-серверных архитектур, сохраняющих все достоинства централизованного администрирования и управления данными, с одной стороны, и дружески настроенных по отношению к пользователю клиентских программ, с другой. Благодаря нормализации удается избежать чрезмерного дублирования данных.
По идее, с точки зрения быстродействия, реляционные СУБД должны проигры-вать сетевым и иерархическим моделям. Однако специальные методы, в частности, индексирование БД, позволяют поддерживать их скоростные характеристики на достаточно высоком уровне.
Развитие РБД
По мере все более широкого распространения реляционных моделей данных крупные поставщики БД расширяли функциональные возможности, повышали производительность в борьбе за место на рынке. В качестве примеров новых функций можно привести следующее:-
Хранимые процедуры
Откомпилированные последовательности SQL-операторов, которые хранятся в БД. Хранимые процедуры исполняются быстрее обычных SQL-операторов, уменьшают объем сетевого трафика и скрывают сложность SQL-выражений от конечного пользователя.
-
Триггеры
Последовательности SQL-операторов, автоматически запускаемые сервером при возникновении определенных, связанных с данными событий. Обычно они используются для поддержания целостности данных и выполнения таких, связанных с модификацией данных, операций, как трассировка (распечатка программой связанных с ее выполнением событий) и аудирование (ведение журнала событий с целью обеспечения безопасности вычислительной системы.).
-
Дублирование и рассредоточение.
Довольно часто с целью повышения произво-дительности, безопасности и готовности информации приходится дублировать данные на удаленных БД. Например, дублировать хранящуюся на удаленном сервере итоговую производственную информацию в центральной БД.
-
Взаимодействие с другими системами.
После того, как электронная почта приобрела широкую популярность, поставщики БД разработали интерфейс, позволяющий посылать определенные почтовые сообщения в момент возникновения определенных, связанных с операциями над данными, событиями.
Тематики
Синонимы
EN
Совет по научным исследованиям и разработкам (США)
—
[А.С.Гольдберг. Англо-русский энергетический словарь. 2006 г.]Тематики
EN
Англо-русский словарь нормативно-технической терминологии > RDB
-
3 relational data base
реляционная база данных
База данных, реализованная в соответствии с реляционной моделью данных.
[ ГОСТ 20886-85]
реляционная БД
База данных, логически организованная в виде набора отношений ее компонентов.
Характерной особенностью реляционной базы данных является структура, выполненная в виде таблиц. Строки таких таблиц соответствуют записям, столбцы - атрибутам (признакам хранимых данных). Например, таблица, в которой имеются столбцы: фамилия, год рождения, место работы, домашний адрес, телефон, а в строках записываются эти сведения о сотрудниках предприятия. Такие данные являются ядром реляционной базы.
Использование реляционных баз данных позволяет:
собирать и хранить данные в виде таблиц;
обновлять их содержание;
получать разнообразную информацию по атрибутам или записям;
отображать полученные данные в виде диаграмм или таблиц;
выполнять необходимые расчеты по материалам базы.
(Терминологическая база данных по информатике и бизнесу [Электронный ресурс])
[ http://www.morepc.ru/dict/]
Системы управления реляционными базами данных
Процесс отделения программ от структур данных завершили, в конечном итоге, реляционные базы данных (РБД).
В РБД все данные представлены исключительно в формате таблиц, или, по терминологии реляционной алгебры, отношений (relation). Таблица в реляционной алгебре - это неупорядоченное множество записей (строк), состоящих из одинакового набора полей (столбцов). Каждая строка характеризует некий объект, каждый столбец - одну из его характеристик. Совокупность таких связанных таблиц и составляет БД, при этом таблицы полностью равноправны - между ними не существует никакой иерархии. Реляционная модель является простейшей и наиболее привычной формой представления данных.
Можно было бы привести более строгое определение, но это не является пред-метом настоящей статьи. Здесь нам важно отметить следующее. РБД позволили моделям данных отражать взаимосвязи прикладной области, а не методы программного доступа к данным и структурам данных. Это огромный шаг вперед по нескольким причинам:
Отражающие прикладную область знаний модели данных являются интуитивно понятными конечному пользователю.
Реорганизация данных на физическом уровне совершенно не влияет на выпол-нение прикладных программ. Одним из важнейших побочных эффектов данного преимущества является появление клиент-серверных архитектур, сохраняющих все достоинства централизованного администрирования и управления данными, с одной стороны, и дружески настроенных по отношению к пользователю клиентских программ, с другой. Благодаря нормализации удается избежать чрезмерного дублирования данных.
По идее, с точки зрения быстродействия, реляционные СУБД должны проигры-вать сетевым и иерархическим моделям. Однако специальные методы, в частности, индексирование БД, позволяют поддерживать их скоростные характеристики на достаточно высоком уровне.
Развитие РБД
По мере все более широкого распространения реляционных моделей данных крупные поставщики БД расширяли функциональные возможности, повышали производительность в борьбе за место на рынке. В качестве примеров новых функций можно привести следующее:-
Хранимые процедуры
Откомпилированные последовательности SQL-операторов, которые хранятся в БД. Хранимые процедуры исполняются быстрее обычных SQL-операторов, уменьшают объем сетевого трафика и скрывают сложность SQL-выражений от конечного пользователя.
-
Триггеры
Последовательности SQL-операторов, автоматически запускаемые сервером при возникновении определенных, связанных с данными событий. Обычно они используются для поддержания целостности данных и выполнения таких, связанных с модификацией данных, операций, как трассировка (распечатка программой связанных с ее выполнением событий) и аудирование (ведение журнала событий с целью обеспечения безопасности вычислительной системы.).
-
Дублирование и рассредоточение.
Довольно часто с целью повышения произво-дительности, безопасности и готовности информации приходится дублировать данные на удаленных БД. Например, дублировать хранящуюся на удаленном сервере итоговую производственную информацию в центральной БД.
-
Взаимодействие с другими системами.
После того, как электронная почта приобрела широкую популярность, поставщики БД разработали интерфейс, позволяющий посылать определенные почтовые сообщения в момент возникновения определенных, связанных с операциями над данными, событиями.
Тематики
Синонимы
EN
Relational data base
База данных, реализованная в соответствии с реляционной моделью данных
Источник: ГОСТ 20886-85: Организация данных в системах обработки данных. Термины и определения оригинал документа
Англо-русский словарь нормативно-технической терминологии > relational data base
-
Хранимые процедуры
-
4 Relational Database
реляционная база данных
База данных, реализованная в соответствии с реляционной моделью данных.
[ ГОСТ 20886-85]
реляционная БД
База данных, логически организованная в виде набора отношений ее компонентов.
Характерной особенностью реляционной базы данных является структура, выполненная в виде таблиц. Строки таких таблиц соответствуют записям, столбцы - атрибутам (признакам хранимых данных). Например, таблица, в которой имеются столбцы: фамилия, год рождения, место работы, домашний адрес, телефон, а в строках записываются эти сведения о сотрудниках предприятия. Такие данные являются ядром реляционной базы.
Использование реляционных баз данных позволяет:
собирать и хранить данные в виде таблиц;
обновлять их содержание;
получать разнообразную информацию по атрибутам или записям;
отображать полученные данные в виде диаграмм или таблиц;
выполнять необходимые расчеты по материалам базы.
(Терминологическая база данных по информатике и бизнесу [Электронный ресурс])
[ http://www.morepc.ru/dict/]
Системы управления реляционными базами данных
Процесс отделения программ от структур данных завершили, в конечном итоге, реляционные базы данных (РБД).
В РБД все данные представлены исключительно в формате таблиц, или, по терминологии реляционной алгебры, отношений (relation). Таблица в реляционной алгебре - это неупорядоченное множество записей (строк), состоящих из одинакового набора полей (столбцов). Каждая строка характеризует некий объект, каждый столбец - одну из его характеристик. Совокупность таких связанных таблиц и составляет БД, при этом таблицы полностью равноправны - между ними не существует никакой иерархии. Реляционная модель является простейшей и наиболее привычной формой представления данных.
Можно было бы привести более строгое определение, но это не является пред-метом настоящей статьи. Здесь нам важно отметить следующее. РБД позволили моделям данных отражать взаимосвязи прикладной области, а не методы программного доступа к данным и структурам данных. Это огромный шаг вперед по нескольким причинам:
Отражающие прикладную область знаний модели данных являются интуитивно понятными конечному пользователю.
Реорганизация данных на физическом уровне совершенно не влияет на выпол-нение прикладных программ. Одним из важнейших побочных эффектов данного преимущества является появление клиент-серверных архитектур, сохраняющих все достоинства централизованного администрирования и управления данными, с одной стороны, и дружески настроенных по отношению к пользователю клиентских программ, с другой. Благодаря нормализации удается избежать чрезмерного дублирования данных.
По идее, с точки зрения быстродействия, реляционные СУБД должны проигры-вать сетевым и иерархическим моделям. Однако специальные методы, в частности, индексирование БД, позволяют поддерживать их скоростные характеристики на достаточно высоком уровне.
Развитие РБД
По мере все более широкого распространения реляционных моделей данных крупные поставщики БД расширяли функциональные возможности, повышали производительность в борьбе за место на рынке. В качестве примеров новых функций можно привести следующее:-
Хранимые процедуры
Откомпилированные последовательности SQL-операторов, которые хранятся в БД. Хранимые процедуры исполняются быстрее обычных SQL-операторов, уменьшают объем сетевого трафика и скрывают сложность SQL-выражений от конечного пользователя.
-
Триггеры
Последовательности SQL-операторов, автоматически запускаемые сервером при возникновении определенных, связанных с данными событий. Обычно они используются для поддержания целостности данных и выполнения таких, связанных с модификацией данных, операций, как трассировка (распечатка программой связанных с ее выполнением событий) и аудирование (ведение журнала событий с целью обеспечения безопасности вычислительной системы.).
-
Дублирование и рассредоточение.
Довольно часто с целью повышения произво-дительности, безопасности и готовности информации приходится дублировать данные на удаленных БД. Например, дублировать хранящуюся на удаленном сервере итоговую производственную информацию в центральной БД.
-
Взаимодействие с другими системами.
После того, как электронная почта приобрела широкую популярность, поставщики БД разработали интерфейс, позволяющий посылать определенные почтовые сообщения в момент возникновения определенных, связанных с операциями над данными, событиями.
Тематики
Синонимы
EN
Англо-русский словарь нормативно-технической терминологии > Relational Database
-
Хранимые процедуры
-
5 set of self-adjoint operators
Макаров: множество самосопряжённых операторовУниверсальный англо-русский словарь > set of self-adjoint operators
-
6 Bioinformatics
Биоинформатика — новое направление исследований, использующее математические и алгоритмические методы для решения молекулярно-биологических задач. В отечественной генетике зарождение этого направления тесно связано со становлением и развитием Института цитологии и генетики СО АН СССР в Новосибирском Академгородке. Первая международная конференция по Б. регуляции и структуры генома в странах СНГ была организована и проведена в этом институте (24–31 августа 1998 г.). Совершенствование экспериментальных методов приводит к экспоненциальному росту молекулярно-биологических данных и возникновению абсолютно новой для биологии междисциплинарной задачи анализа и хранения информации из лабораторий, рассеянных по всему миру. Задачи Б. можно определить как развитие и использование математических и компьютерных методов для решения проблем молекулярной биологии. Выделяют: (1) Задачу поддержания и обновления баз данных. Современная эра в молекулярной биологии началась с момента открытия двойной спирали Уотсоном и Криком в 1953 г. Эта революция породила большой объем данных полученных прямым чтением ДНК из разных участков геномов. Быстрое секвенирование стало возможно 10 лет назад, первый полностью секвенированный геном — геном бактерии Haemophilus influenzae, 1800 т.п.н. В 1996 г. закончено секвенирование первого генома эукариот, генома дрожжей (10 млн п.н.) и секвенирование продолжается со скоростью более 7 миллионов нуклеотидов в год. Знание геномной ДНК в значительной мере сделало возможным ряд фундаментальных биологических открытий, таких как интроны, самосплайсирующиеся РНК (см. РНК-процессинг), обратная транскрипция и псевдогены. Однако существующие базы данных не вполне адекватны требованиям молекулярных биологов: одной из нерешенных проблем является создание программного обеспечения для простого и гибкого доступа к данным. (2) Другой класс задач в большей степени ориентирован на поиск оптимальных алгоритмов для анализа последовательностей. Типичным примером такой задачи является задача выравнивания: как выявить сходство между двумя последовательностями, зная их нуклеотидный состав? Задача решается множество раз в день, поэтому нужен оптимальный алгоритм с минимальным временем выравнивания. (3) Можно также выделить ряд направлений современной Б.: создание и поддержка баз данных (БД) регуляторных последовательностей и белков; БД по регуляции генной экспрессии; БД по генным сетям; компьютерный анализ и моделирование метаболических путей; компьютерные методы анализа и распознавания в геноме регуляторных последовательностей; методы анализа и предсказания активности функциональных сайтов в нуклеотидных последовательностях геномов; компьютерные технологии для изучения генной регуляции; предсказания структуры генов; моделирование транскрипционного и трансляционного контроля генной экспрессии; широкомасштабный геномный анализ и функциональное аннотирование нуклеотидных последовательностей; поиск объективных методов аннотирования и выявления различных сигналов в нуклеотидных последовательностях; эволюция регуляторных последовательностей в геномах; характеристики белковой структуры, связанные с регуляцией; экспериментальные исследования механизмов генной экспрессии и развитие интерфейса, связывающего экспериментальные данные с компьютерным анализом геномов. Первые работы по компьютерному анализу последовательностей биополимеров появились еще в 1960-1970-х годах, однако формирование вычислительной биологии как самостоятельной области началось в 1980-х годах после развития методов массового секвенирования ДНК. С точки зрения биолога-экспериментатора, можно выделить пять направлений вычислительной биологии: непосредственная поддержка эксперимента (физическое картирование (см. Физическая карта), создание контиг (см.) и т.п.), организация и поддержание банков данных, анализ структуры и функции ДНК и белков, эволюционные и филогенетические исследования, а также собственно статистический анализ нуклеотидных последовательностей. Разумеется, границы между этими направлениями в значительной мере условны: результаты распознавания белок-кодирующих областей используются в экспериментах по идентификации генов, одним из основных методов предсказания функции белков является поиск сходных белков в базах данных, а для осуществления детального предсказания клеточной роли белка необходимо привлекать филогенетические соображения. В 1982 г. возникли GenBank и EMBL — основные банки нуклеотидных последовательностей. Вскоре после этого были созданы программы быстрого поиска по банку — FASTA и затем BLAST. Позднее были разработаны методы анализа далеких сходств и выделения функциональных паттернов в белках. Оказалось, что даже при отсутствии близких гомологов, можно достаточно уверенно предсказывать функции белков. Эти методы с успехом применялись при анализе вирусных геномов, а затем и позиционно клонированных генов человека. Алгоритмы анализа функциональных сигналов в ДНК ( промоторов, операторов, сайтов связывания рибосом) менее надежны, однако и они в ряде случаев были успешно применены, напр., при анализе пуринового регулона Escherichia coli. Идет активная работа над созданием алгоритмов предсказания вторичной структуры РНК. Алгоритмические аспекты этой проблемы были разрешены достаточно быстро, однако оказалось, что точность экспериментально определенных физических параметров не позволяет осуществлять надежные предсказания. В то же время, сравнительный подход, позволяющий построить общую структуру для группы родственных или выполняющих одну и ту же функцию РНК, дает существенно более точные результаты. Другим важным достижением, связанным с рибосомальными РНК, стало построение эволюционного древа прокариот и вытекающей из него естественной классификации бактерий, используемой в банках нуклеотидных последовательностей, в частности GenBank. Статистическая информация (в виде предсказания GenScan), последовательности гомологичных белков и последовательности EST являются исходным материалом для предсказания генов в последовательностях ДНК человека программой ААТ. Алгоритмы, объединяющие анализ функциональных сигналов в нуклеотидных последовательностях и предсказание вторичной структуры РНК, используются для поиска генов тРНК и самосплайсирующихся интронов. Одновременный анализ белковых гомологий и функциональных сигналов позволил получить интересные результаты при эволюцию системы репликации по механизму катящегося кольца. Опыт показывает, что надежное предсказание функции белка по аминокислотной последовательности возможно лишь при одновременном применении разнонаправленных программ структурного и функционального анализа. Основное — это приближение теоретических методов к биологической практике. Во-первых, вновь создаваемые алгоритмы все ближе имитируют работу биолога. В частности, был формализован итеративный подход к поиску родственных белков в банках данных, позволяющий работать со слабыми гомологиями и искать отдаленные члены белковых семейств. При этом все члены семейства, идентифицированные на очередном шаге, используются для создания очередного образа семейства, являющегося основой для следующего запроса к базе данных. Другим примером являются алгоритмы, формализующие сравнительный подход к предсказанию вторичной структуры регуляторных РНК. Во-вторых, создаваемые алгоритмы непосредственно приближаются к экспериментальной практике. Так, повышение избирательности методов распознавания белок-кодирующих областей (возможно, за счет уменьшения чувствительности) позволяет осуществлять предсказание специфичных гибридизационных зондов и затравок ПЦР. Наконец, развитие Интернета — электронной почты и затем WWW — сняло зависимость от модели компьютера и операционной системы и сделало программы универсальным рабочим инструментом.Англо-русский толковый словарь генетических терминов > Bioinformatics
-
7 switching technology
технология коммутации
-
[Интент]Современные технологии коммутации
[ http://www.xnets.ru/plugins/content/content.php?content.84]Статья подготовлена на основании материалов опубликованных в журналах "LAN", "Сети и системы связи", в книге В.Олифер и Н.Олифер "Новые технологии и оборудование IP-сетей", на сайтах www.citforum.ru и опубликована в журнале "Компьютерные решения" NN4-6 за 2000 год.
- Введение
- Коммутация первого уровня.
- Коммутация второго уровня.
- Коммутация третьего уровня.
- Коммутация четвертого уровня.
- Критерии выбора оборудования, физическая и логическая структура сети
- Качество обслуживания (QoS) и принципы задания приоритетов
- Заключение
Введение
На сегодня практически все организации, имеющие локальные сети, остановили свой выбор на сетях типа Ethernet. Данный выбор оправдан тем, что начало внедрения такой сети сопряжено с низкой стоимостью и простотой реализации, а развитие - с хорошей масштабируемостью и экономичностью.
Бросив взгляд назад - увидим, что развитие активного оборудования сетей шло в соответствии с требованиями к полосе пропускания и надежности. Требования, предъявляемые к большей надежности, привели к отказу от применения в качестве среды передачи коаксиального кабеля и перевода сетей на витую пару. В результате такого перехода отказ работы соединения между одной из рабочих станций и концентратором перестал сказываться на работе других рабочих станций сети. Но увеличения производительности данный переход не принес, так как концентраторы используют разделяемую (на всех пользователей в сегменте) полосу пропускания. По сути, изменилась только физическая топология сети - с общей шины на звезду, а логическая топология по-прежнему осталась - общей шиной.
Дальнейшее развитие сетей шло по нескольким путям:- увеличение скорости,
- внедрение сегментирования на основе коммутации,
- объединение сетей при помощи маршрутизации.
Увеличение скорости при прежней логической топологии - общая шина, привело к незначительному росту производительности в случае большого числа портов.
Большую эффективность в работе сети принесло сегментирование сетей с использованием технология коммутации пакетов. Коммутация наиболее действенна в следующих вариантах:
Вариант 1, именуемый связью "многие со многими" – это одноранговые сети, когда одновременно существуют потоки данных между парами рабочих станций. При этом предпочтительнее иметь коммутатор, у которого все порты имеют одинаковую скорость, (см. Рисунок 1).
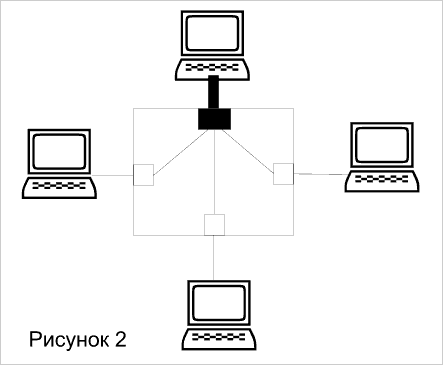
Вариант 2, именуемый связью "один со многими" – это сети клиент-сервер, когда все рабочие станции работают с файлами или базой данных сервера. В данном случае предпочтительнее иметь коммутатор, у которого порты для подключения рабочих станций имеют одинаковую небольшую скорость, а порт, к которому подключается сервер, имеет большую скорость,(см. Рисунок 2).
Когда компании начали связывать разрозненные системы друг с другом, маршрутизация обеспечивала максимально возможную целостность и надежность передачи трафика из одной сети в другую. Но с ростом размера и сложности сети, а также в связи со все более широким применением коммутаторов в локальных сетях, базовые маршрутизаторы (зачастую они получали все данные, посылаемые коммутаторами) стали с трудом справляться со своими задачами.
Проблемы с трафиком, связанные с маршрутизацией, проявляются наиболее остро в средних и крупных компаниях, а также в деятельности операторов Internet, так как они вынуждены иметь дело с большими объемами IP-трафика, причем этот трафик должен передаваться своевременно и эффективно.
С подключением настольных систем непосредственно к коммутаторам на 10/100 Мбит/с между ними и магистралью оказывается все меньше промежуточных устройств. Чем выше скорость подключения настольных систем, тем более скоростной должна быть магистраль. Кроме того, на каждом уровне устройства должны справляться с приходящим трафиком, иначе возникновения заторов не избежать.
Рассмотрению технологий коммутации и посвящена данная статья.Коммутация первого уровня
Термин "коммутация первого уровня" в современной технической литературе практически не описывается. Для начала дадим определение, с какими характеристиками имеет дело физический или первый уровень модели OSI:
физический уровень определяет электротехнические, механические, процедурные и функциональные характеристики активации, поддержания и дезактивации физического канала между конечными системами. Спецификации физического уровня определяют такие характеристики, как уровни напряжений, синхронизацию изменения напряжений, скорость передачи физической информации, максимальные расстояния передачи информации, физические соединители и другие аналогичные характеристики.
Смысл коммутации на первом уровне модели OSI означает физическое (по названию уровня) соединение. Из примеров коммутации первого уровня можно привести релейные коммутаторы некоторых старых телефонных и селекторных систем. В более новых телефонных системах коммутация первого уровня применяется совместно с различными способами сигнализации вызовов и усиления сигналов. В сетях передачи данных данная технология применяется в полностью оптических коммутаторах.Коммутация второго уровня
Рассматривая свойства второго уровня модели OSI и его классическое определение, увидим, что данному уровню принадлежит основная доля коммутирующих свойств.
Определение. Канальный уровень (формально называемый информационно-канальным уровнем) обеспечивает надежный транзит данных через физический канал. Канальный уровень решает вопросы физической адресации (в противоположность сетевой или логической адресации), топологии сети, линейной дисциплины (каким образом конечной системе использовать сетевой канал), уведомления о неисправностях, упорядоченной доставки блоков данных и управления потоком информации.
На самом деле, определяемая канальным уровнем модели OSI функциональность служит платформой для некоторых из сегодняшних наиболее эффективных технологий. Большое значение функциональности второго уровня подчеркивает тот факт, что производители оборудования продолжают вкладывать значительные средства в разработку устройств с такими функциями.
С технологической точки зрения, коммутатор локальных сетей представляет собой устройство, основное назначение которого - максимальное ускорение передачи данных за счет параллельно существующих потоков между узлами сети. В этом - его главное отличие от других традиционных устройств локальных сетей – концентраторов (Hub), предоставляющих всем потокам данных сети всего один канал передачи данных.
Коммутатор позволяет передавать параллельно несколько потоков данных c максимально возможной для каждого потока скоростью. Эта скорость ограничена физической спецификацией протокола, которую также часто называют "скоростью провода". Это возможно благодаря наличию в коммутаторе большого числа центров обработки и продвижения кадров и шин передачи данных.
Коммутаторы локальных сетей в своем основном варианте, ставшем классическим уже с начала 90-х годов, работают на втором уровне модели OSI, применяя свою высокопроизводительную параллельную архитектуру для продвижения кадров канальных протоколов. Другими словами, ими выполняются алгоритмы работы моста, описанные в стандартах IEEE 802.1D и 802.1H. Также они имеют и много других дополнительных функций, часть которых вошла в новую редакцию стандарта 802.1D-1998, а часть остается пока не стандартизованной.
Коммутаторы ЛВС отличаются большим разнообразием возможностей и, следовательно, цен - стоимость 1 порта колеблется в диапазоне от 50 до 1000 долларов. Одной из причин столь больших различий является то, что они предназначены для решения различных классов задач. Коммутаторы высокого класса должны обеспечивать высокую производительность и плотность портов, а также поддерживать широкий спектр функций управления. Простые и дешевые коммутаторы имеют обычно небольшое число портов и не способны поддерживать функции управления. Одним из основных различий является используемая в коммутаторе архитектура. Поскольку большинство современных коммутаторов работают на основе патентованных контроллеров ASIC, устройство этих микросхем и их интеграция с остальными модулями коммутатора (включая буферы ввода-вывода) играет важнейшую роль. Контроллеры ASIC для коммутаторов ЛВС делятся на 2 класса - большие ASIC, способные обслуживать множество коммутируемых портов (один контроллер на устройство) и небольшие ASIC, обслуживающие по несколько портов и объединяемые в матрицы коммутации.
Существует 3 варианта архитектуры коммутаторов:
- переключение (cross-bar) с буферизацией на входе,
- самомаршрутизация (self-route) с разделяемой памятью
- высокоскоростная шина.
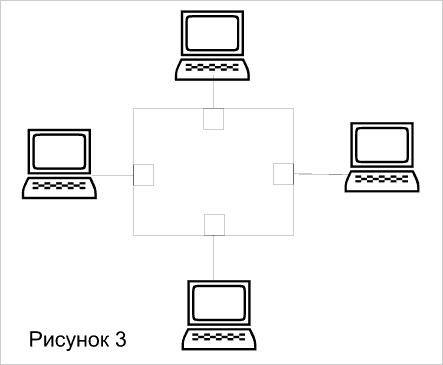
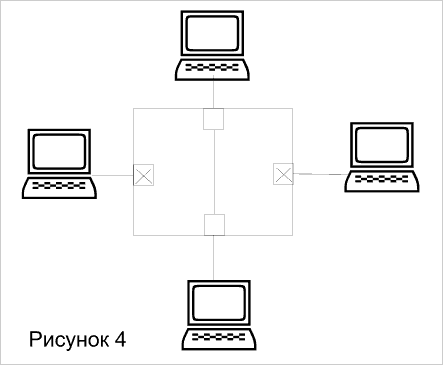
На рисунке 3 показана блок-схема коммутатора с архитектурой, используемой для поочередного соединения пар портов. В любой момент такой коммутатор может обеспечить организацию только одного соединения (пара портов). При невысоком уровне трафика не требуется хранение данных в памяти перед отправкой в порт назначения - такой вариант называется коммутацией на лету cut-through. Однако, коммутаторы cross-bar требуют буферизации на входе от каждого порта, поскольку в случае использования единственно возможного соединения коммутатор блокируется (рисунок 4). Несмотря на малую стоимость и высокую скорость продвижения на рынок, коммутаторы класса cross-bar слишком примитивны для эффективной трансляции между низкоскоростными интерфейсами Ethernet или token ring и высокоскоростными портами ATM и FDDI.
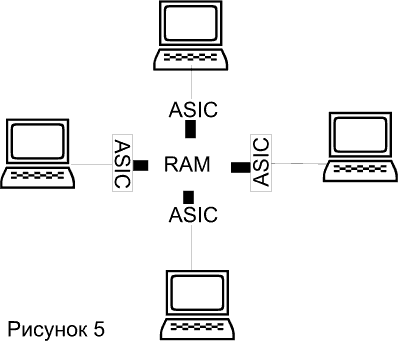
Коммутаторы с разделяемой памятью имеют общий входной буфер для всех портов, используемый как внутренняя магистраль устройства (backplane). Буферизагия данных перед их рассылкой (store-and-forward - сохранить и переслать) приводит к возникновению задержки. Однако, коммутаторы с разделяемой памятью, как показано на рисунке 5 не требуют организации специальной внутренней магистрали для передачи данных между портами, что обеспечивает им более низкую цену по сравнению с коммутаторами на базе высокоскоростной внутренней шины.
На рисунке 6 показана блок-схема коммутатора с высокоскоростной шиной, связывающей контроллеры ASIC. После того, как данные преобразуются в приемлемый для передачи по шине формат, они помещаются на шину и далее передаются в порт назначения. Поскольку шина может обеспечивать одновременную (паралельную) передачу потока данных от всех портов, такие коммутаторы часто называют "неблокируемыми" (non-blocking) - они не создают пробок на пути передачи данных.
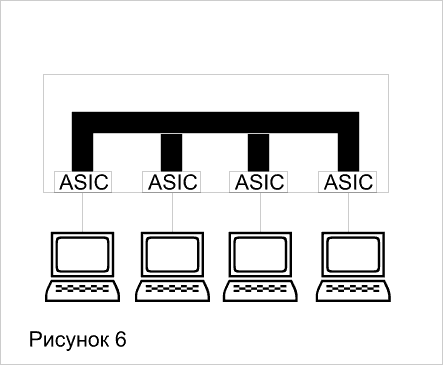
Применение аналогичной параллельной архитектуры для продвижения пакетов сетевых протоколов привело к появлению коммутаторов третьего уровня модели OSI.
Коммутация третьего уровня
В продолжении темы о технологиях коммутации рассмотренных в предыдущем номера повторим, что применение параллельной архитектуры для продвижения пакетов сетевых протоколов привело к появлению коммутаторов третьего уровня. Это позволило существенно, в 10-100 раз повысить скорость маршрутизации по сравнению с традиционными маршрутизаторами, в которых один центральный универсальный процессор выполняет программное обеспечение маршрутизации.
По определению Сетевой уровень (третий) - это комплексный уровень, который обеспечивает возможность соединения и выбор маршрута между двумя конечными системами, подключенными к разным "подсетям", которые могут находиться в разных географических пунктах. В данном случае "подсеть" это, по сути, независимый сетевой кабель (иногда называемый сегментом).
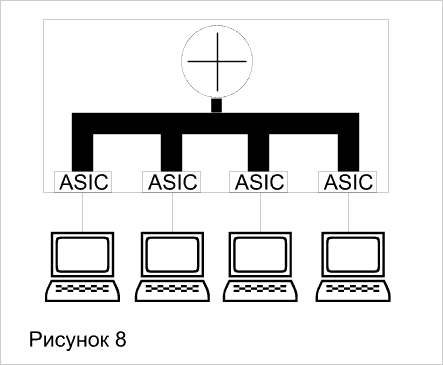
Коммутация на третьем уровне - это аппаратная маршрутизация. Традиционные маршрутизаторы реализуют свои функции с помощью программно-управляемых процессоров, что будем называть программной маршрутизацией. Традиционные маршрутизаторы обычно продвигают пакеты со скоростью около 500000 пакетов в секунду. Коммутаторы третьего уровня сегодня работают со скоростью до 50 миллионов пакетов в секунду. Возможно и дальнейшее ее повышение, так как каждый интерфейсный модуль, как и в коммутаторе второго уровня, оснащен собственным процессором продвижения пакетов на основе ASIC. Так что наращивание количества модулей ведет к наращиванию производительности маршрутизации. Использование высокоскоростной технологии больших заказных интегральных схем (ASIC) является главной характеристикой, отличающей коммутаторы третьего уровня от традиционных маршрутизаторов. Коммутаторы 3-го уровня делятся на две категории: пакетные (Packet-by-Packet Layer 3 Switches, PPL3) и сквозные (Cut-Through Layer 3 Switches, CTL3). PPL3 - означает просто быструю маршрутизацию (Рисунок_7). CTL3 – маршрутизацию первого пакета и коммутацию всех остальных (Рисунок 8).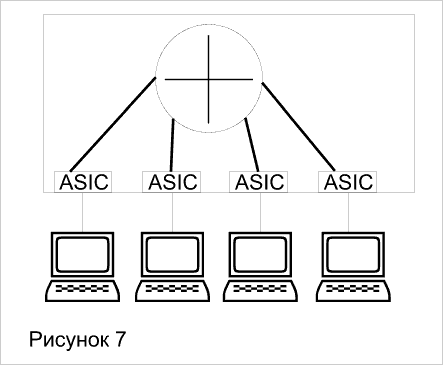
У коммутатора третьего уровня, кроме реализации функций маршрутизации в специализированных интегральных схемах, имеется несколько особенностей, отличающих их от традиционных маршрутизаторов. Эти особенности отражают ориентацию коммутаторов 3-го уровня на работу, в основном, в локальных сетях, а также последствия совмещения в одном устройстве коммутации на 2-м и 3-м уровнях:
- поддержка интерфейсов и протоколов, применяемых в локальных сетях,
- усеченные функции маршрутизации,
- обязательная поддержка механизма виртуальных сетей,
- тесная интеграция функций коммутации и маршрутизации, наличие удобных для администратора операций по заданию маршрутизации между виртуальными сетями.
Наиболее "коммутаторная" версия высокоскоростной маршрутизации выглядит следующим образом (рисунок 9). Пусть коммутатор третьего уровня построен так, что в нем имеется информация о соответствии сетевых адресов (например, IP-адресов) адресам физического уровня (например, MAC-адресам) Все эти МАС-адреса обычным образом отображены в коммутационной таблице, независимо от того, принадлежат ли они данной сети или другим сетям.
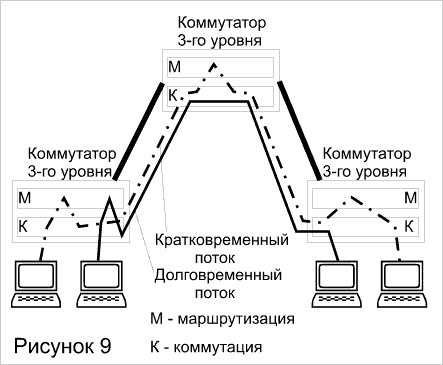
Первый коммутатор, на который поступает пакет, частично выполняет функции маршрутизатора, а именно, функции фильтрации, обеспечивающие безопасность. Он решает, пропускать или нет данный пакет в другую сеть Если пакет пропускать нужно, то коммутатор по IP-адресу назначения определяет МАС-адрес узла назначения и формирует новый заголовок второго уровня с найденным МАС-адресом. Затем выполняется обычная процедура коммутации по данному МАС-адресу с просмотром адресной таблицы коммутатора. Все последующие коммутаторы, построенные по этому же принципу, обрабатывают данный кадр как обычные коммутаторы второго уровня, не привлекая функций маршрутизации, что значительно ускоряет его обработку. Однако функции маршрутизации не являются для них избыточными, поскольку и на эти коммутаторы могут поступать первичные пакеты (непосредственно от рабочих станций), для которых необходимо выполнять фильтрацию и подстановку МАС-адресов.
Это описание носит схематический характер и не раскрывает способов решения возникающих при этом многочисленных проблем, например, проблемы построения таблицы соответствия IP-адресов и МАС-адресов
Примерами коммутаторов третьего уровня, работающих по этой схеме, являются коммутаторы SmartSwitch компании Cabletron. Компания Cabletron реализовала в них свой протокол ускоренной маршрутизации SecureFast Virtual Network, SFVN.
Для организации непосредственного взаимодействия рабочих станций без промежуточного маршрутизатора необходимо сконфигурировать каждую из них так, чтобы она считала собственный интерфейс маршрутизатором по умолчанию. При такой конфигурации станция пытается самостоятельно отправить любой пакет конечному узлу, даже если этот узел находится в другой сети. Так как в общем случае (см. рисунок 10) станции неизвестен МАС-адрес узла назначения, то она генерирует соответствующий ARP-запрос, который перехватывает коммутатор, поддерживающий протокол SFVN. В сети предполагается наличие сервера SFVN Server, являющегося полноценным маршрутизатором и поддерживающего общую ARP-таблицу всех узлов SFVN-сети. Сервер возвращает коммутатору МАС-адрес узла назначения, а коммутатор, в свою очередь, передает его исходной станции. Одновременно сервер SFVN передает коммутаторам сети инструкции о разрешении прохождения пакета с МАС-адресом узла назначения через границы виртуальных сетей. Затем исходная станция передает пакет в кадре, содержащем МАС-адрес узла назначения. Этот кадр проходит через коммутаторы, не вызывая обращения к их блокам маршрутизации. Отличие протокола SFVN компании Cabletron от - описанной выше общей схемы в том, что для нахождения МАС-адреса по IP-адресу в сети используется выделенный сервер.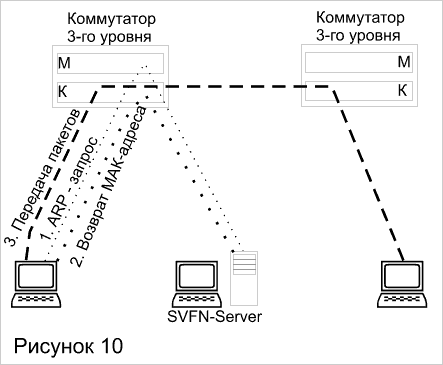
Протокол Fast IP компании 3Com является еще одним примером реализации подхода с отображением IP-адреса на МАС-адрес. В этом протоколе основными действующими лицами являются сетевые адаптеры (что не удивительно, так как компания 3Com является признанным лидером в производстве сетевых адаптеров Ethernet) С одной стороны, такой подход требует изменения программного обеспечения драйверов сетевых адаптеров, и это минус Но зато не требуется изменять все остальное сетевое оборудование.
При необходимости передать пакет узлу назначения другой сети, исходный узел в соответствии с технологией Fast IP должен передать запрос по протоколу NHRP (Next Hop Routing Protocol) маршрутизатору сети. Маршрутизатор переправляет этот запрос узлу назначения, как обычный пакет Узел назначения, который также поддерживает Fast IP и NHRP, получив запрос, отвечает кадром, отсылаемым уже не маршрутизатору, а непосредственно узлу-источнику (по его МАС-адресу, содержащемуся в NHRP-запросе). После этого обмен идет на канальном уровне на основе известных МАС-адресов. Таким образом, снова маршрутизировался только первый пакет потока (как на рисунке 9 кратковременный поток), а все остальные коммутировались (как на рисунке 9 долговременный поток).
Еще один тип коммутаторов третьего уровня — это коммутаторы, работающие с протоколами локальных сетей типа Ethernet и FDDI. Эти коммутаторы выполняют функции маршрутизации не так, как классические маршрутизаторы. Они маршрутизируют не отдельные пакеты, а потоки пакетов.
Поток — это последовательность пакетов, имеющих некоторые общие свойства. По меньшей мере, у них должны совпадать адрес отправителя и адрес получателя, и тогда их можно отправлять по одному и тому же маршруту. Если классический способ маршрутизации использовать только для первого пакета потока, а все остальные обрабатывать на основании опыта первого (или нескольких первых) пакетов, то можно значительно ускорить маршрутизацию всего потока.
Рассмотрим этот подход на примере технологии NetFlow компании Cisco, реализованной в ее маршрутизаторах и коммутаторах. Для каждого пакета, поступающего на порт маршрутизатора, вычисляется хэш-функция от IP-адресов источника, назначения, портов UDP или TCP и поля TOS, характеризующего требуемое качество обслуживания. Во всех маршрутизаторах, поддерживающих данную технологию, через которые проходит данный пакет, в кэш-памяти портов запоминается соответствие значения хэш-функции и адресной информации, необходимой для быстрой передачи пакета следующему маршрутизатору. Таким образом, образуется квазивиртуальный канал (см. Рисунок 11), который позволяет быстро передавать по сети маршрутизаторов все последующие пакеты этого потока. При этом ускорение достигается за счет упрощения процедуры обработки пакета маршрутизатором - не просматриваются таблицы маршрутизации, не выполняются ARP-запросы.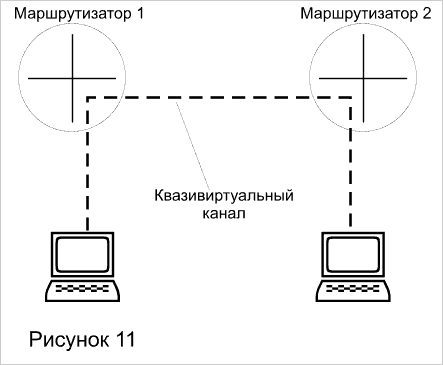
Этот прием может использоваться в маршрутизаторах, вообще не поддерживающих коммутацию, а может быть перенесен в коммутаторы. В этом случае такие коммутаторы тоже называют коммутаторами третьего уровня. Примеров маршрутизаторов, использующих данный подход, являются маршрутизаторы Cisco 7500, а коммутаторов третьего уровня — коммутаторы Catalyst 5000 и 5500. Коммутаторы Catalyst выполняют усеченные функции описанной схемы, они не могут обрабатывать первые пакеты потоков и создавать новые записи о хэш-функциях и адресной информации потоков. Они просто получают данную информацию от маршрутизаторов 7500 и обрабатывают пакеты уже распознанных маршрутизаторами потоков.
Выше был рассмотрен способ ускоренной маршрутизации, основанный на концепции потока. Его сущность заключается в создании квазивиртуальных каналов в сетях, которые не поддерживают виртуальные каналы в обычном понимании этого термина, то есть сетях Ethernet, FDDI, Token Ring и т п. Следует отличать этот способ от способа ускоренной работы маршрутизаторов в сетях, поддерживающих технологию виртуальных каналов — АТМ, frame relay, X 25. В таких сетях создание виртуального канала является штатным режимом работы сетевых устройств. Виртуальные каналы создаются между двумя конечными точками, причем для потоков данных, требующих разного качества обслуживания (например, для данных разных приложений) может создаваться отдельный виртуальный канал. Хотя время создания виртуального канала существенно превышает время маршрутизации одного пакета, выигрыш достигается за счет последующей быстрой передачи потока данных по виртуальному каналу. Но в таких сетях возникает другая проблема — неэффективная передача коротких потоков, то есть потоков, состоящих из небольшого количества пакетов (классический пример — пакеты протокола DNS).
Накладные расходы, связанные с созданием виртуального канала, приходящиеся на один пакет, снижаются при передаче объемных потоков данных. Однако они становятся неприемлемо высокими при передаче коротких потоков. Для того чтобы эффективно передавать короткие потоки, предлагается следующий вариант, при передаче нескольких первых пакетов выполняется обычная маршрутизация. Затем, после того как распознается устойчивый поток, для него строится виртуальный канал, и дальнейшая передача данных происходит с высокой скоростью по этому виртуальному каналу. Таким образом, для коротких потоков виртуальный канал вообще не создается, что и повышает эффективность передачи.
По такой схеме работает ставшая уже классической технология IP Switching компании Ipsilon. Для того чтобы сети коммутаторов АТМ передавали бы пакеты коротких потоков без установления виртуального канала, компания Ipsilon предложила встроить во все коммутаторы АТМ блоки IP-маршрутизации (рисунок 12), строящие обычные таблицы маршрутизации по обычным протоколам RIP и OSPF.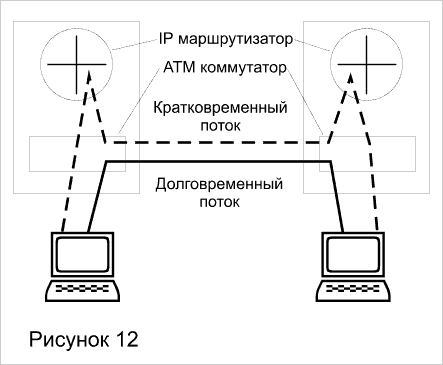
Компания Cisco Systems выдвинула в качестве альтернативы технологии IP Switching свою собственную технологию Tag Switching, но она не стала стандартной. В настоящее время IETF работает над стандартным протоколом обмена метками MPLS (Multi-Protocol Label Switching), который обобщает предложение компаний Ipsilon и Cisco, а также вносит некоторые новые детали и механизмы. Этот протокол ориентирован на поддержку качества обслуживания для виртуальных каналов, образованных метками.
Коммутация четвертого уровня
Свойства четвертого или транспортного уровня модели OSI следующие: транспортный уровень обеспечивает услуги по транспортировке данных. В частности, заботой транспортного уровня является решение таких вопросов, как выполнение надежной транспортировки данных через объединенную сеть. Предоставляя надежные услуги, транспортный уровень обеспечивает механизмы для установки, поддержания и упорядоченного завершения действия виртуальных каналов, систем обнаружения и устранения неисправностей транспортировки и управления информационным потоком (с целью предотвращения переполнения данными из другой системы).
Некоторые производители заявляют, что их системы могут работать на втором, третьем и даже четвертом уровнях. Однако рассмотрение описания стека TCP/IP (рисунок 1), а также структуры пакетов IP и TCP (рисунки 2, 3), показывает, что коммутация четвертого уровня является фикцией, так как все относящиеся к коммутации функции осуществляются на уровне не выше третьего. А именно, термин коммутация четвертого уровня с точки зрения описания стека TCP/IP противоречий не имеет, за исключением того, что при коммутации должны указываться адреса компьютера (маршрутизатора) источника и компьютера (маршрутизатора) получателя. Пакеты TCP имеют поля локальный порт отправителя и локальный порт получателя (рисунок 3), несущие смысл точек входа в приложение (в программу), например Telnet с одной стороны, и точки входа (в данном контексте инкапсуляции) в уровень IP. Кроме того, в стеке TCP/IP именно уровень TCP занимается формированием пакетов из потока данных идущих от приложения. Пакеты IP (рисунок 2) имеют поля адреса компьютера (маршрутизатора) источника и компьютера (маршрутизатора) получателя и следовательно могут наряду с MAC адресами использоваться для коммутации. Тем не менее, название прижилось, к тому же практика показывает, что способность системы анализировать информацию прикладного уровня может оказаться полезной — в частности для управления трафиком. Таким образом, термин "зависимый от приложения" более точно отражает функции так называемых коммутаторов четвертого уровня.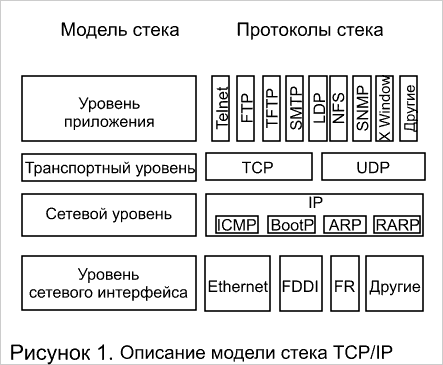
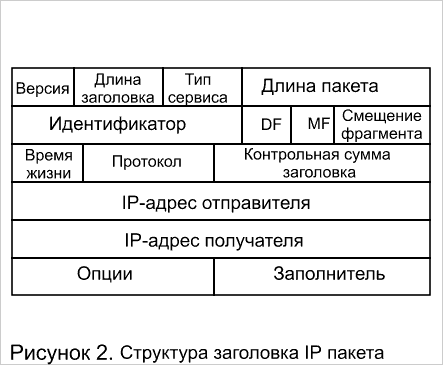
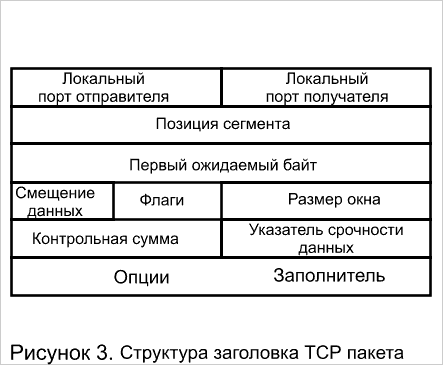
Тематики
EN
Англо-русский словарь нормативно-технической терминологии > switching technology
См. также в других словарях:
Операторов теория — часть функционального анализа (См. Функциональный анализ), посвященная изучению свойств Операторов и применению их к решению различных задач. Понятие оператора одно из самых общих математических понятий. Примеры: 1)… … Большая советская энциклопедия
Операторов теория — Теория операторов раздел функционального анализа, который изучает свойства непрерывных линейных отображений между нормированными пространствами. Вообще говоря, оператор это аналог самой обычной функции или матрицы в конечномерном пространстве.… … Википедия
Перегрузка операторов — У этого термина существуют и другие значения, см. Перегрузка. Перегрузка операторов в программировании один из способов реализации полиморфизма, заключающийся в возможности одновременного существования в одной области видимости нескольких… … Википедия
ВПОЛНЕ НЕПРИВОДИМОЕ МНОЖЕСТВО — множество Млинейных операторов в локально выпуклом топологическом векторном пространстве Е, всюду плотное в алгебре S(E).всех слабо непрерывных линейных операторов в Е;при этом S(E).рассматривается в слабой операторной топологии. Понятие В. н. м … Математическая энциклопедия
ВПОЛНЕ ПРИВОДИМОЕ МНОЖЕСТВО — множество Млинейных операторов в топологическом векторном пространстве Е, обладающее тем свойством, что всякое замкнутое подпространство в Е, инвариантное относительно М, имеет в Еинвариантное дополнение. В гильбертовом пространстве Евсякое… … Математическая энциклопедия
Уравновешенное множество — Множество , принадлежащее векторному пространству , называется уравновешенным, если для любого скаляра , такого что , выполняется соотношение то есть для любого элемента элемент … Википедия
ПОЛУГРУППА ОПЕРАТОРОВ — семейство операторов {Т} вбанаховом или топологическом векторном пространстве, обладающее тем свойством, что композиция любых двух операторов семейства снова принадлежит семейству. Если операторы Т занумерованы элементами нек рой абстрактной… … Математическая энциклопедия
Полугруппа операторов — однопараметрическое семейство линейных ограниченных операторов в банаховом пространстве. Теория полугрупп операторов возникла в середине 20 го века в работах таких известных математиков, как Э.Хилле, Р.Филиппса, К.Иосиды, В.Феллера. Основные… … Википедия
Переопределение операторов — Перегрузка операций (операторов, функций, процедур) в программировании один из способов реализации полиморфизма, заключающийся в возможности одновременного существования в одной области видимости нескольких различных вариантов операции (оператора … Википедия
ПОЛУГРУППА НЕЛИНЕЙНЫХ ОПЕРАТОРОВ — однопараметрическое семейство операторов S(t),0 t< , определенных и действующих в замкнутом подмножестве Сбанахова пространства X, обладающее свойствами: 1) S(t+t)x= S(t)(S(t)x).при х С, t,t>0; 2) S(Q)x=x для любого х С; 3) при каждом х… … Математическая энциклопедия
Теория операторов — Теория операторов раздел функционального анализа, который изучает свойства непрерывных линейных отображений между нормированными пространствами. Вообще говоря, оператор это аналог самой обычной функции или матрицы в конечномерном… … Википедия